以hadoop和Spark为代表的平台上进行数据分析技术
包括实时数据处理,离线数据处理,数据分析,数据挖掘,机器算法分析预测
分布式发布订阅消息系统Kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
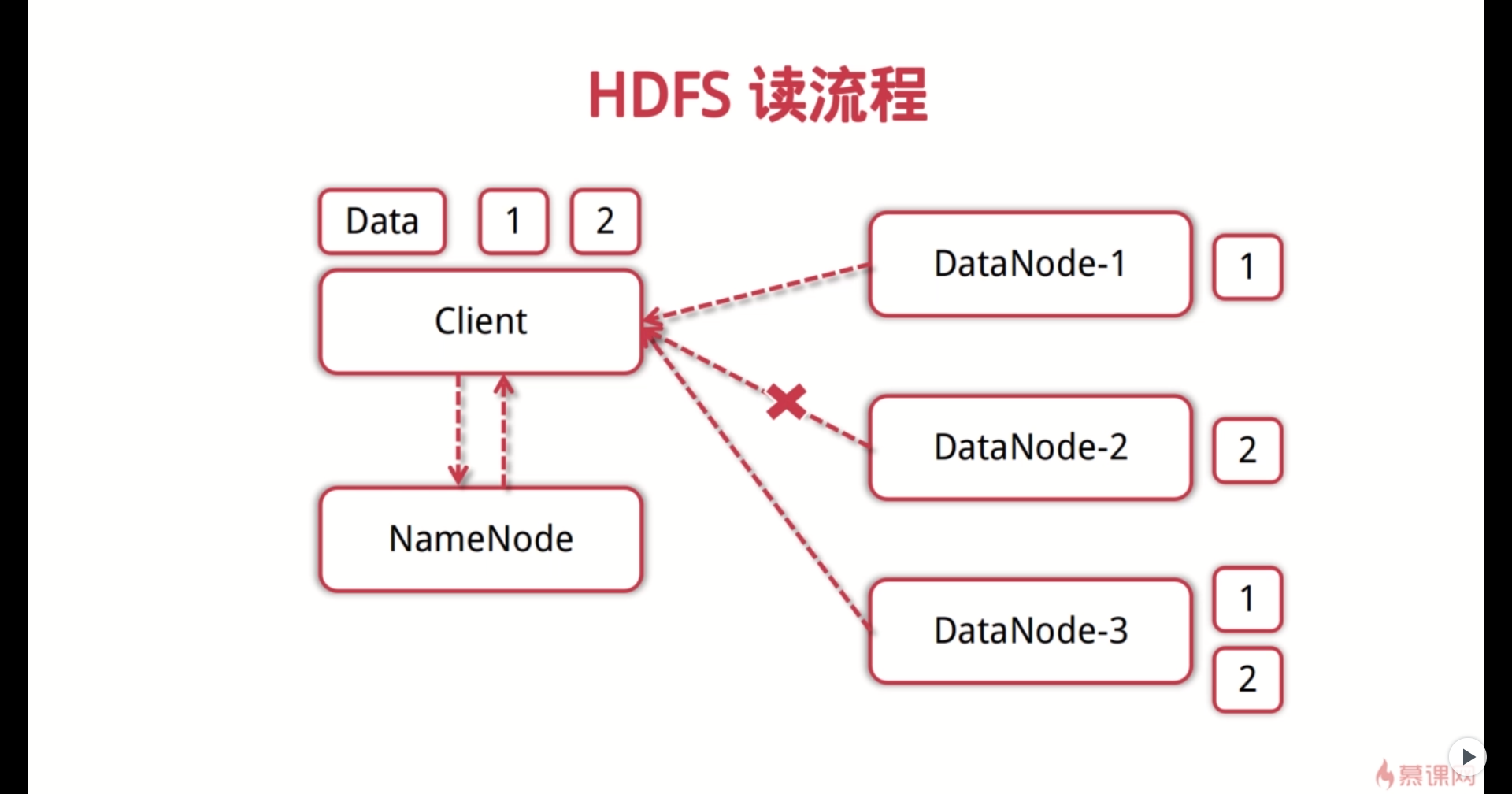
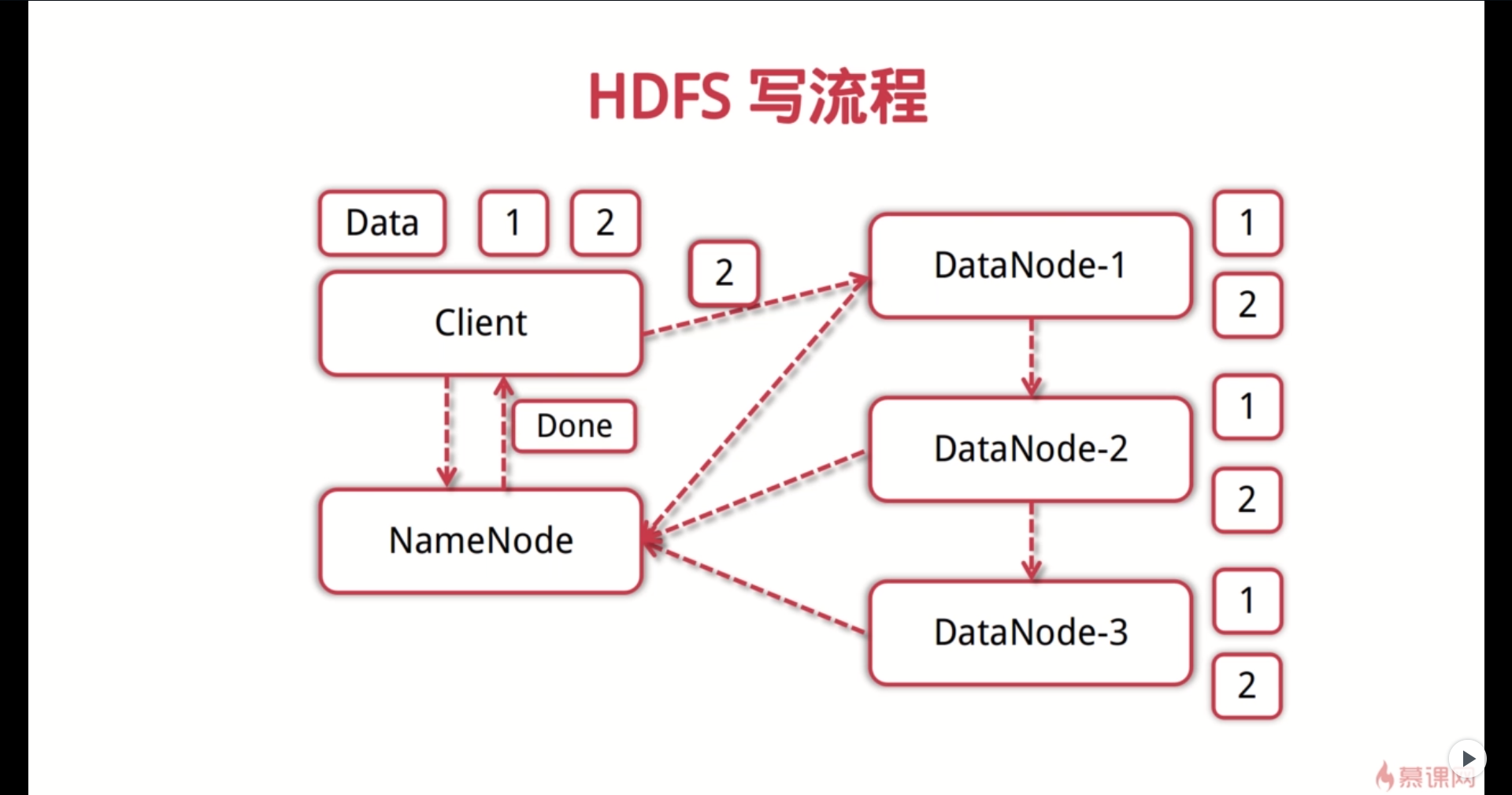
HDFS:分布式文件系统
数据块:默认64M,一般设置128M,备份3份
NameNode(一个):管理文件系统的命名空间,存放文件元数据;维护文件系统的所有文件和目录,文件与数据块的映射;记录每个文件中各个块所在的数据节点信息;
DataNode(多个):存储并检索数据块;向NameNode更新所存储块的列表;
常用Shell命令:
类Linux系统:ls, cat, mkdir, rm, chmod, chown
HDFS文件交互:copyFromLocal, copyToLocal, get, put
python库:hdfs3
MapReduce:分布式计算
YARN:
ResourceManager分配和调度资源;启动并监控ApplicationManager;监控NodeManager
ApplicationMaster为MR(MapReduce)类型的程序申请资源,并分配给内部任务;负责数据切分;监控数据执行和容错
NodeManager管理单个节点的资源;处理来自ResourceManager的命令;处理来自ApplicationMaster的命令
MapReduce编程模型
大文件分成多个分片;每个分片由单独的机器去处理,这是Map方法;将各个机器的计算结果进行汇总并得到最终的结果,这就是Reduce方法
简单示例:
1 | l = ["a","bb","ccc"] |
HBase
高可靠,高性能,面向列,可伸缩,实时读写的分布式数据库
利用HDFS(Hadoop Distributed File System)作为文件存储系统
Spark
基于内存计算的大数据并行计算框架
MapReduce的替代方案,兼容HDFS,HIVE等数据源
弹性分布式数据集RDD(Resilient Distributed Datasets)
基于事件驱动,通过线程池服用线程提高性能